
Google傘下のDeepMind社から最強の囲碁プログラム「AlphaGo Zero」が発表され話題になっていますね。
2016年に初代バージョン「AlphaGo」がトップクラスの棋士に勝ち越したことが話題になって以来、人工知能(Artificial Intelligence, AI)ブームが再燃しているようで、最近はニュースや本屋などでも人工知能関連の情報を多く見かけるようになりました。
しかしながら、人工知能は人類の未来を発展させるものとして期待される反面、併せ持つ危険性に警鐘を鳴らしている著名人も多いようです。(ビル・ゲイツ、スティーブン・ホーキング、イーロン・マスク等)
一体、人工知能には何をさせるべきで、何をさせるべきではないのか?
今回は、「人工知能」について考察します。
人工知能のやっていること
まずは人工知能のやっていることを簡単に理解しておきましょう。
現在ニュースなどで話題となっている人工知能は、「特化型人工知能(特化型AI)」というもので、文字どおり特定の機能に特化して動作するものです。つまり、囲碁のAIは囲碁しか打てませんし、将棋のAIは将棋しか指せません。
ここではそのうちの一つ、オセロの場合で動作を見ていくことにします。
オセロのAIがやっているのは、平たく言ってしまえば「現在の盤面を見て、一番良い手を決める」、これだけです。(まあ実は人間がオセロをプレイしても、やることは同じなのですけれど。)そして、一番良い手を決めるために、「評価関数」というものを計算して使っています。評価関数は、「その手がどのぐらい良い手かを決める計算式」だと理解すれば良いでしょう。
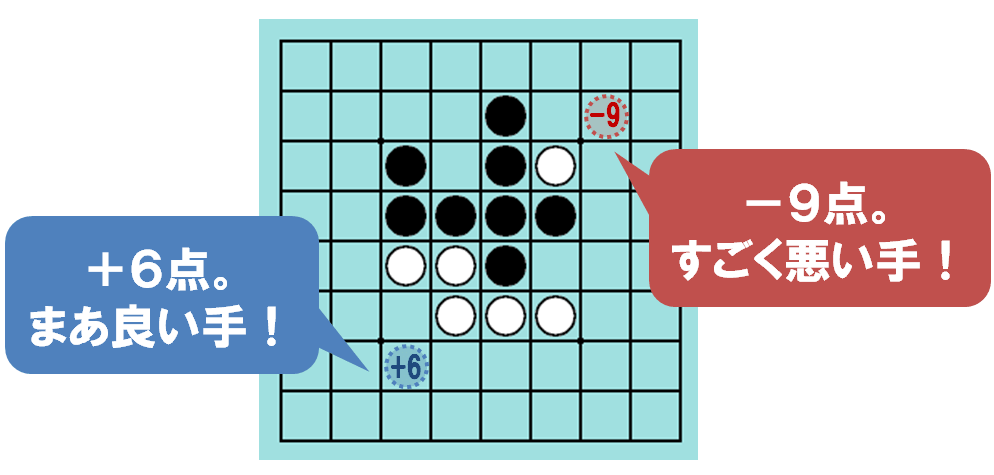 Figure.1 オセロの手の評価値(黒手番)
Figure.1 オセロの手の評価値(黒手番)
(※盤面画像は Booby Reversi より。強いです。)
上の盤面例では、左下の手は+6点で良い手、右上の手は-9点でとても悪い手であることが算出されています。人工知能は、各局面での評価関数を計算し、左下の手のような良い手を選択していくことで、ゲームを進めていきます。(実際には、現在の盤面だけでなく、数手先まで進めた場合の評価関数も同時に計算しながら、総合的に判断して手を決めていきます。これは “探索” と呼ばれます)
さて、この評価関数の精度が、その人工知能の強さに直結しているのは明らかでしょう。従来では、人工知能の開発者自身が “強いプレーヤー” であり、評価関数を自分で考え、人工知能に実装していました。しかし最近では、人工知能にこの評価関数自体を自己生成させ、学習による洗練までもを自律的に行わせることで、比類無い強さを実現しています。
もうこういった分野では、既に人間は人工知能に勝てなくなっています。チェスとオセロでは、20年前に世界チャンピオンが人工知能に敗北しています。囲碁では「AlphaGo」が2016年にトップクラスの棋士に4勝1敗で勝ち越し、今年2017年5月には世界最強と評される棋士に3戦全勝しました。更に、先週発表された後継バージョン「AlphaGo Zero」は、トップクラスの棋士に勝利したバージョンに対して100戦100勝(!)を記録しています。もはや人類が勝つのは絶望的と言ってよいでしょう。更には、ポーカーや麻雀のような不完全情報ゲーム(相手の手札など、自分からは知りえない情報があるゲームのこと)の分野でも、トップクラスのプレーヤーを打ち負かしつつあります。
上述のような話題は、「ついに人工知能が人間を超えた」という文脈で語られることが多いです。では、いずれは人工知能の方が人間よりも常に正しい選択を行えるようになり、人間の判断は不要になるのでしょうか。政治でも教育でも、何でも人工知能に任せてしまえばよい未来がやって来るのでしょうか?
いいえ。
私は、そうではない、いや、そうであるべきではない、と考えます。
人工知能の限界
人工知能は、いずれ価値観の壁にぶつかる
既にチェスや囲碁で人間を凌駕し、このままいけば万能になっていきそうにも思える人工知能ですが、私にはある限界が存在するように感じられます。
人工知能は、いずれ価値観の壁にぶつかるでしょう。
どういうことかというと、価値観の絡む問題には画一的な正解が無く、人によって答えが異なるため、人工知能をもってしても答えを出すことは出来ない、ということです。
「価値観、多様性、そして平和」の話。で挙げた例を見てみましょう。
「最強のスマホはどれだ?」
「牛肉の一番美味しい食べ方は?」
こんな問題に高度な人工知能を投入する必要があるのか?という疑問はひとまず置いておいて(笑)、このような問題には、画一的な正解がありません。答えは人によって異なっていてよく、それぞれの答えが、その人にとっての正解です。人工知能にはこの問いに対する答えは決められません。
次の例はどうでしょうか。
数年前にベストセラーになった、『これからの「正義」の話をしよう』で提示された問いです。
あなたは路面電車の運転士で、時速六〇マイル(約九六キロメートル)で疾走している。前方を見ると、五人の作業員が工具を手に線路上に立っている。電車を止めようとするのだが、できない。ブレーキがきかないのだ。頭が真っ白になる。五人の作業員をはねれば、全員が死ぬとわかっているからだ(はっきりそうわかっているものとする)。
ふと、右側へとそれる待避線が目に入る。そこにも作業員がいる。だが、一人だけだ。路面電車を待避線に向ければ、一人の作業員は死ぬが、五人は助けられることに気づく。
どうすべきだろうか?
引用)『これからの「正義」の話をしよう』(マイケル・サンデル著, 早川書房)
誰もが必ず葛藤してしまうであろう、非常に難しい状況だと思います。そして、この問いにおいて、もし走っているのがあなたが運転する路面電車ではなく、人工知能が運転する自動運転車であれば、この命題に答えを出さなければいけないのは人間ではなく人工知能であるということになります。
さて、人工知能が、このような場合の判断を下してしまって良いのでしょうか??
「価値観」は、人間が決めるべきである
このような問題に答えを出すためには、「価値観の決定」が必要になります。価値観の決定とは、「何を “良し” とするか」を決めることです。オセロなどのゲームでいえば、ゲームのルールがこれにあたると考えることができるでしょう。人工知能の開発者はオセロのAIに「最終的に自陣の石が多い方が、”良い”」という価値観を予め定義していると理解し直すことができます。
しかしながら、価値観は人によって異なります。価値観が異なれば、結論が真逆になることすらありえます。オセロのルールが、「最終的に自陣の石が “少ない” 方が勝ち」に変わるだけで、最強のオセロAIは最弱のAIに成り果てます。
前項では、人工知能が得意とする囲碁やオセロを「こういった分野」と曖昧にまとめましたが、もう少し明確に表現するとこうなります。何が「良い」かを明確に定義できる分野。実装面では「評価関数が定義・計算可能である」と言い換えてもよいでしょう。価値観の絡む問題は、人工知能の得意とするところではないのです。
もちろん、とりあえずエイヤっと決めちゃうことは可能です。開発者が自分自身の個人的な価値観を人工知能に反映させてしまうことや、今や人工知能自身に自己生成させることも可能でしょう。しかし、「開発者が勝手に決めた価値観」や「人工知能が勝手に生成した価値観」による判断を、人間はすんなり受け入れることができるでしょうか。
映画『アイ,ロボット(I, Robot)』には、少女と屈強な刑事が同時に事故に遭い、刑事からの “少女のほうを助けろ” という命令を無視して “生存確率が高い” という基準で刑事のほうを救ったロボットが描かれています。以来その刑事はロボットを毛嫌いするようになるのですが、もし人間が、人工知能による判断を全く疑問を持たずに受け入れてしまうのであれば、もはやそれは人間的ではなく、むしろロボット的であるとさえ言えるでしょう。人間は、他の誰でもない自らの価値観を持って、自分自身で判断を行い、その判断の結果に責任を持つべきではないでしょうか。
価値観は人間が定義し、人工知能が書き換え不可能な領域に格納しなければならない。
アイザック・アシモフの示した、ロボット三原則 の拡張・抽象化表現として、これを主張しておきたいと思います。
価値観を人工知能自身に決めさせる権利を与えることは、人工知能に人権を与えることと同義になるでしょう。2017年現在では、まだ所謂「強いAI」と呼ばれる、自我や自意識を持った(ドラえもんや、アトムのような)人工知能は全く実現の糸口さえ掴めていませんが、そのような人工知能が実現可能になったときに、この問題が顕在化すると予想されます。
実社会における議論
幾つかの分野では、上記のような問題は、既に実社会でも議論が必要な段階にあります。
実用化に向けて急速に開発が行われている自動運転技術においては、自動運転車が事故を起こした場合の責任についての議論が進められています(自動運転における損害賠償責任に関する研究会 – 国土交通省)。主な論点は、事故の責任がドライバー側にあるのか、自動運転システム(およびそのメーカー)側にあるのか、などです。実務面では、損害賠償や自動車保険の役割について法整備も含めた対応が進められていくでしょう。
しかしながら、人工知能がどうしても事故を回避できない状況に陥った時、「どのような基準に従って判断を下すように実装されているのか」についてはメーカー側の実装に依存しており、開示されていません。そのまま直進すれば老人と子供の二人をはねるがハンドルを切ればどちらかは助かるとき、A社の自動運転車は老人を助け、B社の自動運転車は子供を助けるような事態が発生すると考えられます。多数派の意見を統一基準として採用するか、ドライバーは自動運転車を購入する際にこの究極の選択について予め答えるよう要求されるのかもしれません。いずれにせよ、メーカーはこのような価値観ロジックについて開示を迫られることになるでしょう。
また、軍事利用においては、2012年にアメリカ国防総省が人間の判断を介さない自律殺傷兵器の開発を禁止し、2017年にこれを恒久的なものにしました。人工知能の自己判断による人類への攻撃について、”NO” という判断を下したと言えます。高度な人工知能による人類への反逆は古くからSF作品でもよく見られる設定ですが、そうなる可能性自体を未然に防ぐ社会的意思決定が既に現実に行われているということに重要な意義があると思います。
最近は、「将来政治も人工知能がやるようになるだろう」なんて乱暴な意見も散見されますが、それは人間が人工知能の言いなりになる世界を許容すると言っていることと同義であることを認識すべきです。ゲームのAIが自己生成する評価関数において、その計算式にどんな意味があるのかもう人間には理解が出来ません。人工知能の裁判官が死刑を求刑しても、何故そのように判断されたのか計算式を見ても人間には理解できないということです。
2045年には(ちょっと早い気がしますが)、圧倒的な人工知能が完全に人間を超越し、科学技術の進歩を担い世界を変革する技術的特異点(シンギュラリティ)が到来すると言われています。しかし、シンギュラリティが到来した後の世界でも、「価値観の決定」は人類が担う仕事として在り続けるべきだと考えます。
「人間は考える葦である」(B. パスカル)
どんな状況にあっても、考えることをやめないことが人間が人間たりえるために必要なことだと思います。
今回のまとめ
- 人工知能はルールが明確に決まっているゲームが得意。もう人間は勝てない。
- 人工知能は価値観の壁を越えられない。いや、越えさせてはならない。「何を “良し” とするか」は、人間が決めるべきだ。
- シンギュラリティの到来後は、「価値観の決定」が人類に残される最後の仕事になるだろう。これだけは人工知能に委ねてはならない。自分たちのことは自分たちで決めましょう。
ではでは今回はこの辺で。
この記事をいいね!と思ったら購読やシェアをしていただけるとうれしいです。












